线上非开源的:
https://www.ttslist.com/ TTSlist.com chatTTS 音色库 /AI声音编号库/音色抽卡不烦恼
ComfyUI是一款基于节点工作流的Stable Diffusion图形界面工具 ,在进行视频分镜创作时,可借助相关插件和特定流程来实现。
分镜创作流程 :先使用如DeepSeek等AI创作工具,通过输入详细的视频创意需求,获取包含场景描述的智能分镜设计。接着,依据分镜内容书写生图咒语,将其放入ComfyUI中,结合已训练好的Lora模型生成定帧画面。
在这个过程中,要注意生图咒语的优化,可采用关键词分层的方式,从主体、场景、风格、细节四个层次细化描述,通过多轮迭代、分段生成等手段逐步提升画面质量 。
Storyboard 专用插件 推荐搜索 GitHub 上的以下关键词:
ComfyUI-Storyboard(有开发者尝试制作分镜生成节点)ComfyUI-ControlNet-Story(结合ControlNet的分镜控制流程)
bash
复制
"ComfyUI" + [插件名称] # 例如 "ComfyUI Storyboard" 或 "ComfyUI ControlNet"推荐工作流配置
多镜头生成:使用 Batch Processing 节点配合动态提示词
角色一致性:结合 IPAdapter+角色 LoRA
分镜布局:使用 Layout-Parser 节点控制画面构图
时间轴管理:Timeline 节点(社区插件)
二、开源分镜专用模型
Storyboard-Diffusion(专门训练的分镜风格模型)AnimeStoryboard-v3(二次元分镜专用)Cinematic-LoRA(电影分镜风格适配器) 辅助工具模型
- ShotComposer(镜头语言解析模型)
- SceneParser(场景元素分割模型)
- Dialogue2Story(台词转分镜的文本模型) 三、推荐工作流架构(可自行搭建)
graph TD
A[剧本输入] --> B(脚本解析器)
B --> C{镜头类型判断}
C -->|全景| D[广角构图+环境控制]
C -->|特写| E[面部增强+浅景深]
C -->|动作| F[动态模糊控制]
D/E/F --> G[ControlNet构图锁定]
G --> H[角色一致性引擎]
H --> I[批量生成节点]
I --> J[自动排版输出]四、替代方案推荐
- 专业工具
- Storyboarder(开源分镜软件+AI插件)
- Boords(在线协作平台)
- Shotgrid(影视级流程管理) | Column 1 | Column 2 | Column 3 | | --- | --- | --- | | 工具名称 | 下载地址 | 备注 | | Storyboarder | 官网 | 开源免费,支持PSD导出 | | Boords | 官网 | 在线工具,免费版有导出限制 | | Shotgrid | 官网 | 企业级工具,需申请试用 | | D-ID | 官网 | 需API密钥,有免费额度 |
-
AI视频生成工具 • D-ID(动态分镜生成)
-
RunwayML(场景连续性控制)
-
Kaiber(音乐节奏适配分镜) 五、学习资源
-
GitHub 项目: •
Awesome-AI-Storyboarding(分镜AI资源汇总)
ComfyUI-Workflow-Examples中的Film分类
- 案例参考: • 《火影忍者》AI分镜开源项目( GitHub 搜索Naruto-Storyboard-AI)
- 新海诚风格分镜LoRA(CivitAI平台)
建议关注HuggingFace和CivitAI平台每周更新的
storyboard相关tag,该领域目前处于高速发展阶段,每个月都有新工具出现。对于需要精准控制的分镜制作,推荐结合使用ControlNet+IPAdapter+Segment Anything的”三位一体”控制方案。
B站老白分镜教程
AI做分镜和动画的可行性,老白连线Onestory技术总监_哔哩哔哩_bilibili
https://onestory.art/dashboard
https://github.com/comfyanonymous/ComfyUI_examples
关键注意事项
-
依赖项安装: • 部分插件需要 Python 库支持(如OpenCV、PyTorch),可通过
pip install -r requirements.txt安装- 缺失节点报错时,检查控制台提示的缺少的模块名称
-
版本兼容性: • ComfyUI 版本需≥1.7(2024年后插件普遍要求此版本)
- 模型与 SD 版本匹配(SD1.5/SDXL)
-
版权声明: • CivitAI模型注意查看License(部分禁止商用)
- 使用LoRA时需遵守训练数据来源协议
配音文本批量
目前测下来最好的是 Index-TTS 1.5 ,可以从刘悦大佬的技术博客里学习下载一键包, 教程优先看这个UP主:AI王知风,目前看下来讲的最适合小白的教程
https://space.bilibili.com/3031494
- 批量Excel表字段设计:


-
高级参数:
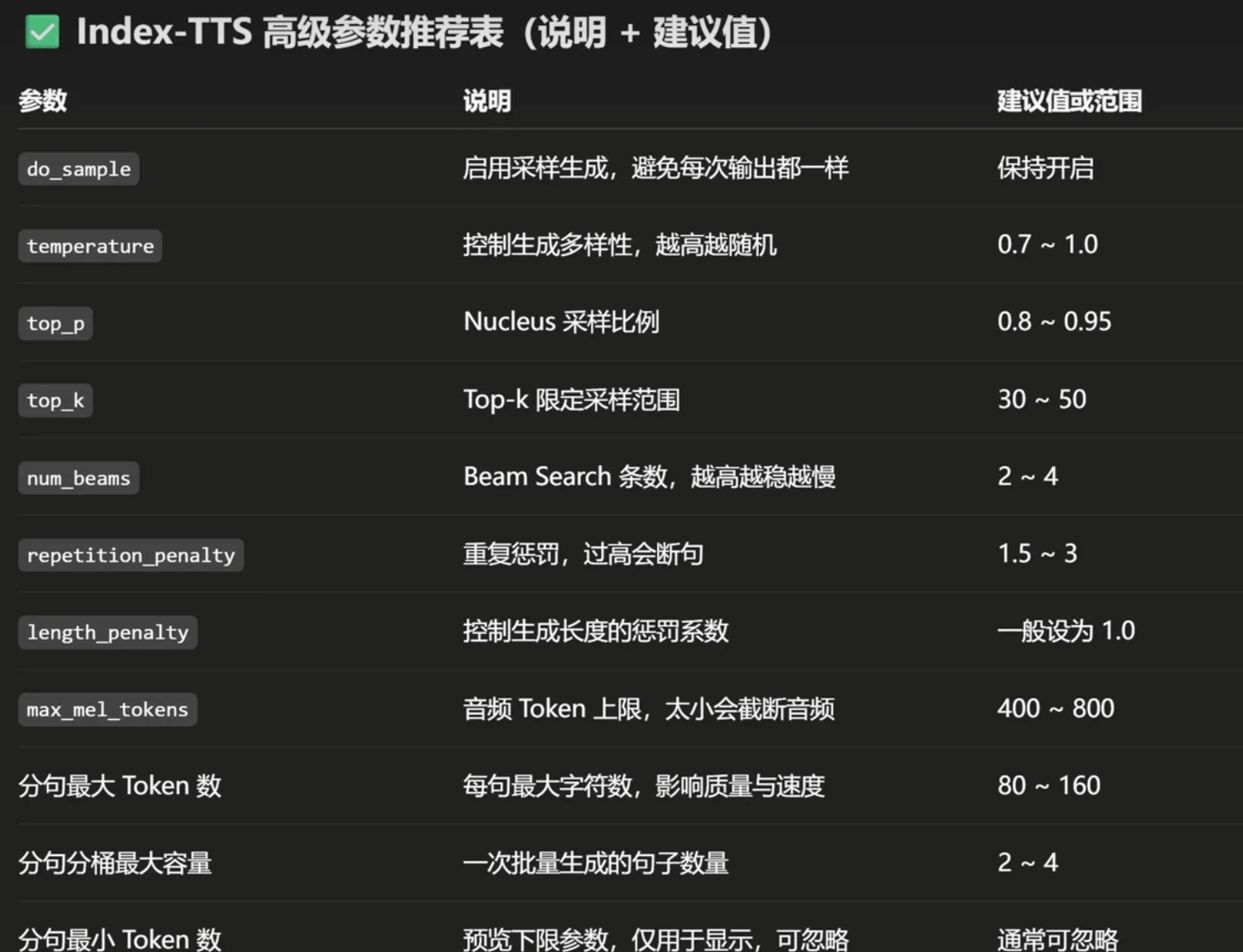
-
翻唱用 RVC 数据集训练标准,格式尽量用wav,采样率48k好于40k,CPU 线程根据自己电脑情况(任务管理器—>性能—>逻辑处理器的数值)设置,越大越好,说话人id单人默认为0 教程参考: https://www.bilibili.com/video/BV1oj7eznEPB?spm_id_from=333.788.player.switch&vd_source=1c8cb094f5379f021095253ff5bb43d4
| Column 1 | Column 2 |
|---|---|
| 分类 | 内容 |
| 时长 | 最好控制在 40 分钟到一小时之间时间太短,容易出现咬字不清、音色漂浮的问题时间太长,训练时间增加,收益递减 |
| 音质 | 不要噪音 不要混响去掉一切环境声清除一切白噪声 |
| 音域 | 低音 中音 高音把你能发的音域全部唱出来 破音要避开 走音无所谓音域是底层逻辑 越宽 越稳 模型的泛化能力越强 |
| Column 1 | Column 2 |
|---|---|
| 描述 | 推荐 选项 |
| 是否仅保存最新的 ckpt 文件以节省硬盘空间 | 否 |
| 是否缓存所有训练集至显存,10min 以下小数据可缓存以加速训练,大数据缓存会炸显存也加不了多少速 | 否 |
| 是否在每次保存时间点将最终小模型保存至 weights 文件夹 | 是 |
| Column 1 | Column 2 |
|---|---|
| 显卡 | 推荐 batch_size |
| 3060 12G | 6~8 |
| 4060 8G | 4~6 |
| 4060 Ti 16G | 8~10 |
| 4070 12G | 10~12 |
| 4070 Super 16G | 12~14 |
| 4080 16G | 16~20 |
| 4090 24G | 24~32 |
| A100 40G | 64~96 |
伴奏人声分离中针对人声模型选择,结合英文理解: dereverb (去混响 ) DeEcho (去回声 )、 DeReverb (去混响 )
| Column 1 | Column 2 | Column 3 | Column 4 | Column 5 |
|---|---|---|---|---|
| 模型名称 | 训练数据特点 | 核心功能侧重 | 适用场景建议 | 效果差异(对比常规模型) |
| HP2_all_vocalsHP3_all_vocals | 包含多声部、多歌手人声数据 | 兼顾多声部层次,通用音色转换 | 多歌手合唱、复杂编曲素材 | 多声部融合好,但单人主唱音色精准度稍弱 |
| ✅ HP5_only_main_vocal | 专注单一主唱人声纯净数据 | 聚焦主音色高精度还原 | 单人主唱歌曲、突出 solo 场景 | 主音色细腻,但多声部适配性差 |
| onnx_dereverb_By_FoxJoy | 经 “去混响” 预处理的人声数据 | 先净化(去混响)再做音色转换 | 带混响干扰的素材(如现场翻唱) | 有效削弱混响,但过度处理可能让声音干涩 |
| VR-DeEchoDeReverb | 侧重 “去回声 + 去混响” 优化数据 | 声学修复(去回声 / 混响)+ 音色转换 | 有环境音(回声、混响)的素材 | 环境音净化强,声音更 “贴耳”,细节可能损失 |
| VR-DeEchoNormal | 侧重 “去回声” 优化数据 | 去回声处理 + 基础音色转换 | 带回声干扰的普通素材 | 回声削弱明显,保留一定自然度 |
💡 > 欢迎分享文章,或是 来信 与我交流